-
Startups or Trolling?
I’m starting to think that the recruiters might be trolling me, based on how ludicrous the concepts are for some of these startups. Also, one of them was looking for “strong Frontend Engineers,” noting “The tech-stack is primarily javascript, but prior experience is not a must have.”
If you want to experience getting cold emails from recruiters without actually receiving email, just click the button!
-
Solar Panel A/B Testing
About a week and a half ago I got an email from the electric company called “Energy Use Alert” letting me know that so far I had used $5.18 worth of electricity during the billing cycle and that my monthly bill was projected to be somewhere between $8.80 and $11.90. This email included a helpful tip: “Want to lower your bill? Reduce your electricity use during On-Peak hours.”
I have a ground-based solar array with 26 panels, and they are filthy. I suspected that washing the solar panels would do more for my electric bill than avoiding using appliances at dinner time.
A quick review of the internet told me that solar panel washing is a scam. You should not pay someone to wash your solar panels because it does not help. Washing solar panels leads to a 1-2% improvement, maybe 3% if they are really dirty.
This seemed preposterous to me, as there is very obviously a whole bunch of opaque dirt and bird crap between my solar panels and the sun. I see a daily dip in production when the earth arranges itself so that there is a tree between the solar panels and the sun, and the tree is not particularly large nor particularly near the solar panels. Temporary tree-shade is a bigger problem than persistent dirt?
This, of course, meant that I needed to test my hypothesis. I got some distilled water and a window-washing doohickey and started washing half the panels. Sadly, I am not tall enough to reach all of them, so I ended up washing almost a third of the panels.

In order to compare the performance of the washed ones to the unwashed ones, I did my split as a checkerboard because it would be a bad idea to only wash the ones that are shaded by the tree. I washed them on June 30, so the July report for energy produced to date is going to give a good sense of the difference in production between the clean panels and the dirty ones. I’ve circled the clean ones.
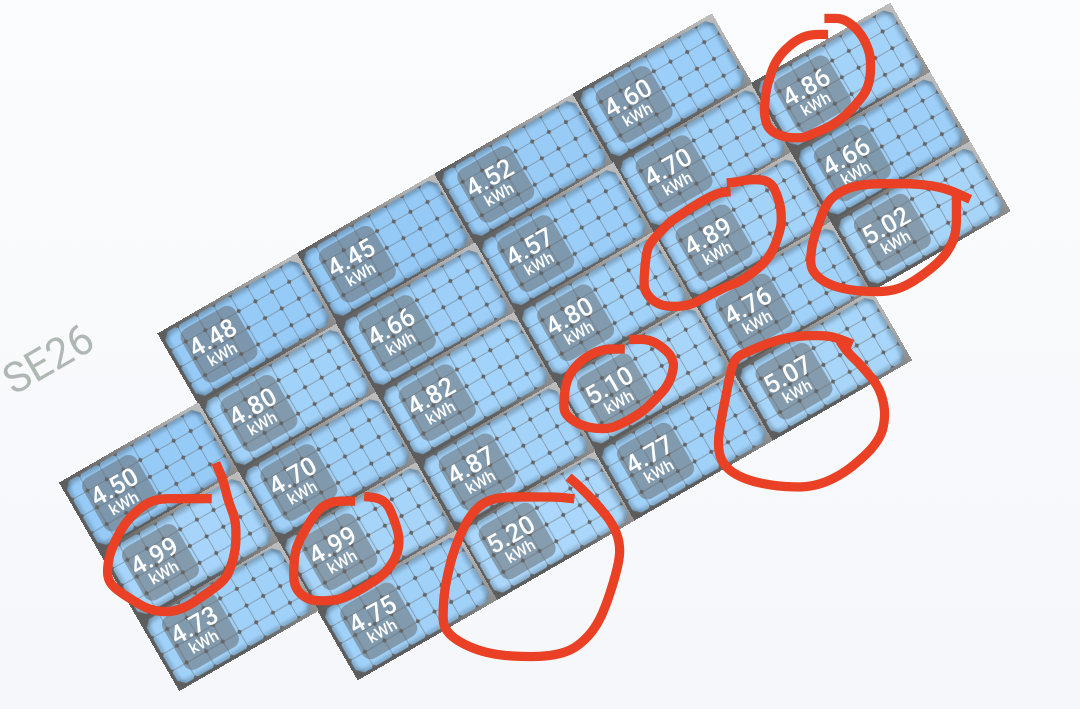
The sample size is small enough that I’m not going to bother to calculate a confidence interval for how much better the clean ones are doing than the dirty ones. Back of the envelope, I’m pretty comfortable saying that I’m seeing a roughly 5% improvement in production due to cleaning. The best improvment from dirty -> clean come from the part of the array that doesn’t get shaded by the tree.
Like many good A/B tests, I have a pretty strong takeaway here: I need to get out the ladder and clean the rest of the solar panels.
-
How to Use a Google Service Account for Google Sheets API with Node Without Using Environment Variables
It’s time for the important tech content that is part of being a serious software professional with a blog. It’s an amazing coincidence that recruiters are reaching out to me about jobs using React and Node.js – the exact same stack that is used by the team that I am on!
Since I am not a recipe blogger, I am not going to hide the important stuff at the end, after my personal story. If you are using a service account and not OAuth2 to authenticate to the Google Sheets API, the standard advice is to put the location of the credential into an environment variable. Which is ok, I guess, for just fussing around on your laptop but is never going to fly in production. I need the credential to be in a config file.
const getAuthToken = async function() { const auth = new google.auth.GoogleAuth({ keyFile: "/path/to/credential.json", scopes: ["https://www.googleapis.com/auth/spreadsheets"], }); const authToken = await auth.getClient(); return authToken; }This has been working for me. I think I found it suggested in one of the READMEs in the GitHub repo for the npm library for the Google APIs. I hunted a very long time before I found it, and based on what I saw in the various dead ends that I encountered along the way, I am not the first person to have been in this situation.
Back to our meandering and pointless narrative.
As has been a theme at work lately, people want decisive business information reported to them in spreadsheets. Not to brag, but the number of KPIs that we have has been taking off like a rocketship!!! Thus, I spent the past few days making a reporting tool in Node and React where you enter some information on a page and click a button and BOOM! the data you want magically appears in a Google Sheet.
Do you want to use Node to make your own Google Sheets reporting tool? The first thing that you need to do is to read this blog post by Mandeep Singh Gulati who figured it out and did a really good job of writing it up. I found this to be about a thousand times more useful than Google’s documentation of the Sheets API. Admitedly, I’ve never been particularly impressed by Google’s documentation of their APIs, but the Sheets API is really well documented! But the blog post that I linked to is still way, way better. Read that blog post and refer to the documentation and you will also be well on your way to having a fullstack JavaScript reverse ETL pipeline (or whatever).
The other thing that I missed upon my first reading of the documentation is that the request body is an object named
resource. So if you are writing[["hi", "from"], ["my", "spreadsheet"]]to some cells of your spreadsheet, you would do something like// Assume that you already have the spreadsheetId and auth const request = { spreadsheetId, auth, valueInputOption: USER_ENTERED, range: "B1:C2", resource: {[["hi", "from"], ["my", "spreadsheet"]]} }; const response = await sheets.spreadsheets.values.update(request);When it comes to the React side of things, you are on your own. Since React is made out of magic and lets you do silly things, I did silly things. For example, when you click the button that sets off this entire process and runs a bunch of database queries before sending the results to Google Sheets, I take away the button. That is right, the mere act of clicking the button makes it go away until the data has landed in the sheet. You can not keep clicking and clicking and clicking while you wait because the button is not there anymore. This is why React is a valuable part of your analytics pipeline.
Speaking of KPIs, the mere act of creating an empty page with a button in React took about 100 lines of boilerplate spread out across six files – before the button even did anything!
-
Creatures Polluting My Cookies
OK, I think we are safe from recruiters trying to meet some KPI about reaching out to me about companies that want to hire someone who likes using React more than I do.
Recently there has been some creature(s) that has been making noises in the evening. At first I thought that maybe one of the neighbors have a cat that was yelling, but that didn’t seem quite right. The sound is sort of meow-like, but it’s not exactly a meow.
By now YouTube probably thinks that I have a toddler at home because I have been spending a lot of time searching for the sounds that various animals make. Sound of bobcat. Sound of catbird. Sound of coyote. I’m starting to get ads for various animal sound apps that are meant to entertain children.
The other day I had an idea. I live in the sort of suburb where people do light farming. Lots of chickens and bee hives around here. Maybe someone is keeping some sort of noisy animal in their yard. The noise is at a frequency that I can (mostly) hear with both ears, so I can (mostly) tell what direction it’s coming from. It really seems like it’s coming from a residential neighborhood and not an undeveloped area.
Now my ad-tracking cookies think that I want to know about online streaming services, as I have been searching for information about peacocks (or, as they prefer to be called, peafowl). According to YouTube, the sound seems to match. Then I went to check the best website in the world for answering the question “What’s that sound I hear outside,” and I logged in to Nextdoor. Nothing showed up in the feed, but a search for “peacock” did turn up a post from April where someone found a peacock in her yard. So it seems that there are
peacockspeafowl in the neighborhood.The next thing to do is to go on a wild
goosepeafowl chase and follow the sound.
-
Eventually I Will Get Bored Reviewing Startups
I got another email from a recruiter looking to staff up a startup. This is starting to get somewhat perplexing to me. It is June. Isn’t this the time of year that droves of new graduates are unleashed upon the job market? I feel like new graduates are going to have more enthusiasm for the prospect of taking a job with a company that has a good chance of failing in the next two years, as they are in the “build your skills and then move on” phase of their careers. Plus, the new graduates are probably all studied up on some of the irrelevant things that come up at job interviews.
The most recent startup that is not compelling enough to lure me away from my current job is in the grocery sector. At first when I hear the term “grocery store,” I think of large chains like Wegmans or Kroger which I’m assuming have pretty robust infrastructure that integrates their point-of-sale systems with their inventory and distribution operations. It took me a moment to realize that this startup is targeting the smaller stores. When I lived in Ithaca I did a lot of my shopping at the Win Li market out on Elmira Rd. because it was cheaper than Wegmans, and I was broke (WHERE WERE THE STARTUPS THEN???). The Win Li market, as you might guess, also appeals to people who prefer foods from Asia. This startup offers a plug-and-play online store for small groceries.
This company is pretty solidly in the B2B space and with a specialized niche. I’m not aware of any other companies offering similar products. As they note in their pitch, they compare their product to Shopify – but with the key difference that grocery stores have a lot more SKUs than your typical mom-and-pop small business and that real-time inventory tracking needs to be done both via the online order system as well as the point-of-sale system. If this product really is first-to-market and best-in-class, it’s a strong contender in this space. Switching to a different online storefront is going to be really annoying, so as long as they are good enough, they are likely going to have strong customer retention.
You can see from the careers part of their website that they are really concerned about the wide variety of SKUs in your typical grocery store. They are hiring people to come up with the taxonomy of all the products. With an emphasis on “ethnic” markets, this adds the wrinkle that not everything is known by the same name to everyone. For example, the winter melon has a lot of different names across various parts of Asia. When people buy their winter melons at Safeway, they are probably OK with them being called “winter melon”; when people buy their winter melons at the market that caters to people from “the old country,” they probably expect this gourd to go by its regional name.
What you can’t see on their website (so I don’t have any idea if they are worried about this or not) is a strategy to handle real-time inventory management. For something like produce – especially delicate, seasonal produce – you can’t keep too much on hand. If people are buying the items both in store and online, you need to update the inventory numbers after each transaction. Otherwise people will be sad when they order things online and it turns out that they are out of stock. This isn’t too much of a problem for small stores. As they reach out to larger stores, it’s going to take more sophisticated infrastructure to keep this data up-to-date. For me, these are the more interesting problems. I’m curious about how they manage integrating the online sales with the point-of-sale systems and maintaining an accurate inventory count.
The startup is a little bit coy about how the groceries should handle fulfillment and delivery of the online orders. They are also unclear about what they have been doing for the past seven years or so. They’ve been in business since 2013 and only started building out this product last year. What were they doing before?
Overall seems like an strong concept with interesting technical problems. This seems like the sort of company that could get purchased by a much larger company. They offer remote work and the sort of salary that one would expect from a VC-funded startup. I just wouldn’t join a company this small and a product this new unless I personally knew one of the people involved in the project.
-
More Emails From Startups
It looks like some web-scraping robot has recently added my name to a prospect list for recruiters because I have received three unsolicited emails in the past week! The first one (something about healthcare staffing) didn’t reply to my follow-up questions, but recruiters 2 and 3 did. I also got an email from LinkedIn saying that 17 people have looked at my profile in the past week. Hello, 17 people!
Remember, if you are recruiting for a company with a solid business model, generous compensation, and a commitment to remote work, I am always interested in hearing from you! I’ve been with my current employer for almost eight years, so you need to have a pitch that is more compelling than “we are spending VC money like it is going out of style.” Yesterday I built an analytics reporting tool in Node.js. Last week I used full-stack JavaScript to improve the interactivity of components of a math game in an HTML Canvas. Next week I’ll be using Python to build transforms (that run in AWS Lambda) to make our data in Redshift more useful for people. If you give me an empty server, I can stand up a webserver with the LEMP stack and get a basic site going. I have also studied statistics at the graduate level and can do hypothesis testing and model building in R. People come to me when they need someone to write complex SQL queries. Do you need random crap to get done? I do a lot of random crap! And, as I mentioned, I’ve been here for eight years. I stick around and then explain to people that the reason that the code does something that seems to be mysterious and counter-intuitive is because of a decision that was made in 2014 and exactly what will break if you change it.
Enough self-promotion. I’d promised that I was going to review the startups that contact me.
First off, I liked the recruiter for this startup way more than the recruiter for the previous startup. The emails used normal language and not hyperbole. As you might recall the previous one referred to the company as a “rocketship” which always triggers my instinctual reaction of “I am not an astronaut.” We talked about normal business things like normal people having a normal business conversation!
Today’s startup is also in the staffing space. As we continue to build out a “gig economy” there are more and more companies that are connecting people to gigs. This particular company has positioned itself in the “one type of gig” space rather than the “lots of types of gigs but sort of within a general category” model that is used by competitors such as TaskRabbit and Thumbtack. The elevator pitch here is clearly something like “TaskRabbit [or Thumbtack] but for exectutive assistants.” Fancy Hands (which I have used in the past!) is another company in this space. Based on my previous experience with Fancy Hands, one key difference is that you can have the Fancy Hands assistants do one-off tasks (it was super-helpful when I was moving cross-country, especially since I needed things done that required a mix of different skills), but this week’s startup is focused on dedicated assistants for people doing important business executive work. I used Fancy Hands eight years ago, and they seem to still be in business, so this definitely seems like a sustainable business model. The success or failure of this company is more likely to be contingent on running things correctly (including SEO) than “disrupting” something.
One thing that sets this company apart is that they are matching executives with virtual assistants who live in the local area (no idea what radius counts as local). This is going to be easy for people who live in locales with a lot of gig economy workers, such as any major city in California. Other places are going to be more difficult to find a match; this is going to limit the potential for growth. This emphasis on local workers is going to help with time zone issues. It’s also going to appeal to people who are kind of racist about off-shore contractors in various parts of Asia. I don’t know if there is some sort of policy about whether these local virtual assistants can be expected to do in-person work for the executive – or what sort of friction that would cause.
More concerning for me is that the same locales that have a lot of gig economy workers are starting to implement a lot of gig economy worker laws. My own employer has had to shift many of our “independent contractors” to “part time employees of a third-party service” in order to stay on the right side of all of the various laws in all of the various places. Maybe this startup will hire the assistants as employees and not as contractors? If that expense is already planned for in the business model, then that is a point in their favor, but that’s pretty uncommon for the gig economy.
The rest of my concerns about this startup are pretty nitpicky – and they may have already considered them. Due to the nature of my own work, I’m always attuned to data privacy situations, so I’m sort of curious about how this startup is handling those issues. I’m assuming that executives of small but real companies sometimes work with sensitive information, and there may be issues with sharing some of that with a third party contractor. This might be less of an issue for companies that don’t store personal data about eight-year-olds in California.
Overall, seemed like a pretty plausible company. If I were looking to work for a company that’s only been around for a year and that relies on investor capital (rather than profits) for cash flow and that paid notably less than what I currently make, I would consider the opportunity. However, I work for a profitable company that has been around for almost 20 years and that has put up with me for eight years, so this startup does not seem to be a fit.
Keep the emails coming! Is your startup compelling enough to lure me away? Does one of your KPIs measure whether or not I respond to your cold email (I respond!)? Maybe you are looking for someone to do consulting work? I value my nights and weekends, so my consulting rate is many times the hourly rate that I’m paid at my day job, but I am happy to hear about your project!
-
Startup Review
It’s time to introduce a new feature to the blog: Startup review. When recruiters from startups send me unsolicited emails about joining their team, I will post my thoughts on the company’s business model. I won’t mention the company by name. If you are interested in the company, let me know, and I will put you in touch with the recruiter.
On Friday I heard from a recruiter who used the words “rocketship” and “disrupt” in the subject line. He pitched the company as “Visual Clubhouse.”
The concept here is that celebrities and influencers would teach synchronous classes via Zoom. People who bought access to the class would then be able to ask the presenter questions in real-time. So, for example, Kelley Deal could give an online workshop on knitting and making handbags, and long-time fans of The Breeders (such as myself) could pay money to attend via Zoom and ask Kelley about her favorite way to sew on a zipper. The celebrity/influencer would get 80% of the proceeds, and the start-up would get 20%. (I don’t think that either Kim nor Kelley have signed up for this platform. This is just a hypothetical example.)
There are some obvious upsides here. People love celebrities. People really want to interact with celebrities. If you look at the replies to tweets by celebrities – even in cases where the Twitter feed is obviously managed by a PR firm – there are a lot of people expressing their undying adoration and hoping for a response. Selling access to celebrities sounds like a good idea.
It’s an entirely virtual product; they’re selling an experience. This means that they don’t have to worry about supply chains, warehousing, and logistics. It also means that a customer doesn’t need to “use up” the items in a purchase before ordering more.
But let’s put the glitter of celebrity aside for a moment and think about the realities of this business model. From many years of experience in the online education business, I have some real concerns.
-
Class size vs. interactivity vs. revenue. You need a small class size in order to offer meaningful interaction with the celebrity. You need a high price point to make money with a small class size. Are people willing to spend a lot of money to Zoom with a real celebrity? How happy are they going to be with the experience, as the celebrity’s time is going to be divided between the primary educational content and all the other participants. People are going to be very upset by tech glitches and other problems if they spent a lot of money.
-
Quality of content. It is hard to put together good educational content that can be delivered over Zoom. If someone is going to pay big bucks, they’re probably going to expect high-quality content. You might have seen “Master Class” show up in your Facebook ads. Master Class (asynchronous) puts a lot of time and effort into producing the educational content. Once it’s done, they can keep selling it again and again and again. Not all celebrities and influencers are good teachers. If people are going to be paying more money than they do for watching Facebook Live or a YouTube video, they probably expect better quality content.
-
Synchronous classes and schedules. YouTube is always there. If I want to watch a YouTube video about how to recharge the refrigerant in my car’s a/c system, I can do that any time of the day or night. I have a lot of options to choose from. If I don’t like one, I can try another. This startup’s model of synchronous classes means that no matter how much you hype a lesson, once it is over, it is over. Time zones are a huge issue; times that are convenient in California are not great in Europe. They’re even worse in India.
-
Zoom. They are based on Zoom, a company that makes technical decisions such as having
//appear in its UUIDs (which are sent as URL parameters to their API – they recommend double URL encoding). -
Churn. There is also going to be a fair amount of churn among both A-list celebrities and their fans. Barack Obama does not have time to teach a weekly course on constitutional law over Zoom. Let’s imagine that he does give a lesson in something via this platform. How many of his fans are going to be interested in paying a lot of money to learn something else from a different celebrity. In business-speak, I worry that customer acquisition costs will not stack up favorably against lifetime value.
-
Moderation and customer behavior. If someone pays a lot of money to be in a real-time video chat with a celebrity, that person might feel empowered to say anything at all to the celebrity. I can assure you that someone is going to do something inappropriate at some point. Are celebrities going to want to moderate their own classrooms? Or will the startup need to provide human or AI class monitors? Zoom’s built in tools for moderating meetings are not up to this challenge. Maybe this startup is all stocked up on software engineers who are experts on AWS Kinesis and has a plan in place for AI content moderation in real time. However, the position that the recruiter was emailing me about was using Node.js and React, which is just general site-building stuff. (I’m actually mildly interested in why they are using React. I’m on a team that primarily uses a Node.js/React stack, and there are definitely drawbacks to React. We’ve moved some of our public-facing pages to something leaner because the heft of React was causing problems with our SEO.)
-
Content drift. The startup is currently limiting itself to lessons being offered by top notch celebrities and plans to open things up later to run-of-the-mill influencers. At some point they are going to reach the point where one of the lessons is something along the lines of “Dita Von Teese teaches burlesque.” This sort of content is very popular, but once you get enough of it, your site is not going to be the place that people associate with “Barack Obama teaches constitutional law.” It’s also not going to help any issues that you have around moderating paricipants’ contributions. You’ll also end up with self-taught health and fitness influencers giving some really bad and dangerous advice.
-
Content drift part II. From a business perspective, this sort of generally-popular content is probably a lot more profitable than specialty experiences. While there aren’t a lot of people who would pay to see the same lesson about the third amendment multiple times, there are probably a lot more people who would pay to see the same lesson about a particular burlesque technique multiple times. Esports athletes probably also have the cachet to offer the same synchronous lesson multiple times with high customer lifetime value. But at this point you move away from Neil deGrasse Tyson teaches awe-inspiring physics-stuff and more towards “OnlyFans with Zoom” or “Twitch with Zoom.” This makes money in the short-term, but there is a real risk that OnlyFans or Twitch will subsume this style of content delivery and then seriously cut into the audience for this startup.
The recruiter also dodged my question about the location of the job. I’ve reached a point where if my primary work location is not within bicycling distance of my home, then I am not interested. If the job can be done from inside my house? Even better.
Are you a recruiter for a company that wants an employee like me? Or do you want free publicity for your company when I write a blog post about your business model? Send me email! Be sure to include the primary work location and the compensation for the role in your email. Note that emails containing the terms .NET, ASP, C#, or Java will be routed directly to my spam filter.
-
{kind=link}
subscribe via RSS